

Using HAPPE
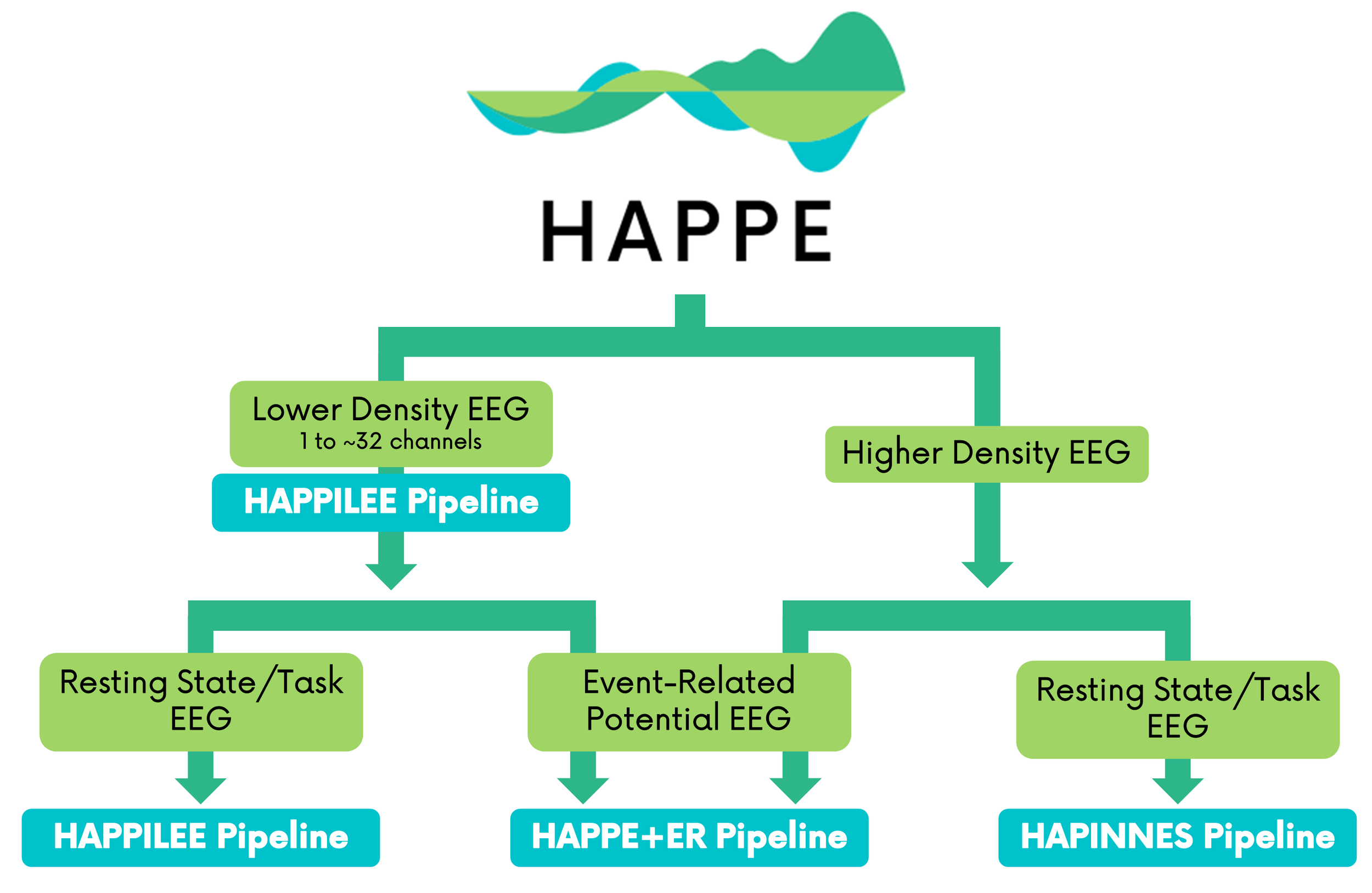
HAPPE (pronounced “happy”) is open-source software for processing electroencephalography (EEG) data (Gabard-Durnam et al., 2018; Lopez et al., 2022; Monachino et al., 2022).
HAPPE was developed to address an urgent need in the developmental neuroimaging community for standardized, automatable processing approaches that perform well with acquisition constraints and artifact levels in developmental and patient populations.
To facilitate implementation of HAPPE, we include example datasets of EEG files for each pipeline with visualizations at each step of HAPPE processing.
Find the HAPINNES Dataset HERE
Find the HAPPE+ER Dataset HERE
Find the HAPPILEE Dataset HERE
—
After downloading the HAPPE folder from GitHub, we recommend:
Reading the User Guide for HAPPE.
2. Downloading and processing the example dataset following the tutorial.
3. Running several of your files with visualizations on to examine how default HAPPE settings perform with your data.
4. When you are satisfied with your HAPPE user-specified options, you may run your data in batch (recommended for speed) by turning off visualizations.